
同样是计算资源,CPU与GPU的虚拟化难度似乎有着云泥之别。时至今日,GPU的虚拟化技术似乎还充斥着特殊硬件和专有软件。
当然,本文的主题并非“So Nvidia, FUCK YOU!”,也不打算探讨是什么原因造成了这种局面。本文仅是讲述作为一个不愿意付出额外成本的用户,如何利用不太光明正大的手段让vGPU技术为我所用。
Changelog
Update#1 At 2023.10.03
本文写作于PVE7.3 + vGPU 15.1时代,其中的部分链接已经失效,内容也存在过时之处。
本次更新为适配PVE8.0-2 + vGPU 16.1,内核版本为6.2。
现有安装步骤中的内容不会更改,因为新的安装流程可能与博主安装时不同。从零开始安装的读者应当注意辨识过时的内容/命令。
对于有必要更新的内容,更新将会以提示的形式加入文中,可以通过搜索Update#1找到。
本次更新新加入了升级流程,该部分适用于已经安装旧版本,希望升级到新版本的读者。
Update#∞ At 2024.03.02
悲报:17.0已经移除P40支持[1],所以这大概是最后一次主动升级更新了。同时要是没什么离谱的bug要很离谱的更新来修,本篇文章就算是告一段落了。
不过vGPU 16.x要2026年中才EOL[2],暂且不用担心有bug没人修。等EOL了也该捡下一波垃圾了,博主已经在期待人均大模型时代下柜的卡了。
本次更新改了一下已经千疮百孔的驱动下载站链接,姑且找了一个能用的,之后再失效就只能由大家自行寻找了。顺便更新到了当前最新的vGPU 16.4,不过更新流程没什么好写的。
就这样。
背景知识
在动手之前应当先了解一下本次的“受害者”,本节主要介绍一些关于vGPU的基础信息。
vGPU是什么?
vGPU是NVIDIA的GPU虚拟化方案。其目的是在允许多个虚拟机共享同一个物理GPU的同时,为虚拟机提供近似原生的GPU功能与性能。这套方案由用于提供计算能力的硬件计算卡与负责传递各种调用的驱动共同实现,用户需要同时为GPU的硬件与vGPU实例授权二者付费。
认证机制
在宿主机,仅有企业级GPU会被vGPU宿主驱动识别。消费级显卡无法合法地作为vGPU硬件使用。宿主机驱动不需要授权。
在虚拟机,vGPU子设备无法合法地使用除vGPU客户驱动外任何驱动,而vGPU客户驱动理论上需要向NVIDIA购买授权才能使用。vGPU子设备根据能力不同分为A、B、C、Q四类,也具有不同的授权价格。未授权的驱动会随加载后经过的时长逐步限制子设备性能,直至几乎完全无法使用。
子设备型号
以NVIDIA GRID P40-8Q为例。P40代表派生出此子设备的宿主机GPU型号为P40,8代表本子设备可以使用8GB的显存,而最后一位字母Q标明了本子设备的能力。
- Q-series:虚拟工作站模式,子设备表现为与母设备相同的全功能GPU。需要最昂贵的vWS授权。
- C-series:虚拟计算服务器,只提供Linux系统驱动,仅支持CUDA。需要vCS授权。
- B-series:虚拟PC,支持DiriectX等图形API,用于桌面虚拟化。需要vPC授权。
- A-series:虚拟应用程序,支持DiriectX等图形API,用于应用虚拟化。需要vApp授权。
在这里,只需要记住最贵的vWS授权对应的Q类设备具有全功能就够了。[3][4]
共享模式
vGPU的共享模式分为Time-Sliced和MIG两种。
Time-Sliced模式下,GPU的核心由运行在宿主机的宿主驱动调度。当前选中的虚拟机计算任务可以使用全部的计算单元,其他的任务处于暂停状态。但同一物理设备给不同虚拟机分配的显存互相独立,且必须大小一致。
MIG,即Multi-Instance GPU,是新一代的vGPU共享模式。在这种模式下,GPU的核心变得可分。多个虚拟机的计算任务可以同时运行在核心的不同计算单元上。同时,此模式下不同虚拟机不再必须要分配完全相同的显存大小。但是,此模式下一个虚拟机闲置的计算资源无法被其它实例利用。
但是需要注意的是,MIG仅在A100/H100等GPU上可用[6]。截至本文成文时,这些GPU的价格距离个人用户可接受仍有较大距离。同时,个人很少会有多虚拟机并行需求,MIG模式会导致大量算力被浪费。因此,后文全部基于Time-Sliced模式。
软硬件方案
介绍完vGPU对软硬件的限制,博主相信不会有人想去按正规方式使用vGPU。作为不商用且很难被追责的个人用户,该聊聊可以绕过限制的方案了。
Rust-based vgpu_unlock
vgpu_unlock[7]是一个通过修改型号,patch驱动等方式绕过限制的方案。本项目的功能分为面对宿主和面对虚拟机两部分。
对于宿主机,本方案可以通过修改型号与宿主驱动的方式,将消费级显卡伪装成具有相同核心型号的专业卡,进而成功生成子设备。需要注意的是,并非所有型号都可以通过这种方式伪装。vgpu_unlock目前仅支持:
- 除了GTX970的GTX9xx
- GTX10xx
- GTX16xx与RTX20xx
更具体的支持列表可以参考此教程。
对于虚拟机,本方案通过修改启动流程、hook、回报虚假参数等方式,令vGPU子设备伪装成消费级显卡,从而可以在虚拟机使用不需要授权的消费级显卡驱动。
FastAPI-DLS
FastAPI-DLS[8]是对NVIDIA用于分发授权证书的Delegated License Service的FastAPI实现。本方案的原理是模拟正规流程的激活服务器,对虚拟机进行许可证授权。因此,本方案仅解决了子设备授权问题,仍需要配合具有vGPU功能的专业卡使用。
vGPU_LicenseBypass
vGPU_LicenseBypass[9]是一种利用驱动刚启动试用时间的方案。本方案的功能包括将不限制性能的时间从20分钟改为一天,同时每天定时重启系统,以达成一直不受限的目标。同样的,本方案仅解决授权问题,未绕过硬件限制。
抉择
博主最终选择了FastAPI-DLS,主要原因如下:
FastAPI-DLS不需要介入宿主或虚拟机做任何修改,只负责生成一张虚假的授权证书。整套vGPU方案除授权服务器虚假外与正规流程无异。而只要不更新虚拟机驱动,证书验证算法不变,理应具有等同于正规授权的稳定性。
而曾经具有高昂价格的硬件,在因设备更迭需要大规模下柜,流入二手市场时已经不再昂贵。甚至因为专业卡没有视频输出与主动散热,其单位价格性能要高于消费级设备。
综合来说,此方案具有远超剩余两种方案的稳定性与体验,而几乎不需要额外付出成本。在博主的应用场景下是最优选择。
如果你打算使用不支持vGPU的消费级GPU,可能需要选用vgpu_unlock方案。可以参考补充资料部分的其他教程。
宿主机配置
确定了方案,接下来就该开工了。
不同于消费级驱动,NVIDIA的vGPU驱动并不提供公开下载。理论上需要先取得许可证,才能从授权管理面板下载所需驱动。好在有许多好心人分享了驱动资源,只需直接下载即可。
博主选择了从此网站下载了适用于Linux KVM的vGPU 15.1版本驱动包,文件名为NVIDIA-GRID-Linux-KVM-525.85.07-525.85.05-528.24.zip。此驱动包同时包含了需要的宿主和几类虚拟机驱动,下一节的虚拟机驱动也出自本驱动包。
对于PVE,下载名称内包含
Linux-KVM的项目即可。例如vGPU 16.1驱动包名称为
NVIDIA-GRID-Linux-KVM-535.104.06-535.104.05-537.13.zip。博主PVE的5.15内核可以很好地兼容15.1本版本的驱动。因为NVIDIA并未公布支持的具体数据[10],所以对于其他组合博主不保证一定可以使用,请自行测试。
环境准备
如果你还没有启用vfio,执行以下命令。
echo vfio >> /etc/modules
echo vfio_iommu_type1 >> /etc/modules
echo vfio_pci >> /etc/modules
echo vfio_virqfd >> /etc/modules
update-initramfs -k all -uPVE默认使用了名为nouveau的非专有驱动来实现基础的功能。但为了让将要安装的宿主机驱动能正常工作,需要屏蔽掉nouveau。当虚拟机试图访问MSR时,KVM会主动触发系统崩溃[11]。需要通过配置文件忽略MSR并抑制日志。
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
echo "options kvm ignore_msrs=1 report_ignored_msrs=0" > /etc/modprobe.d/kvm.conf
update-initramfs -k all -u
reboot宿主机驱动
接下来安装构建驱动需要的软件包。
apt install build-essential dkms mdevctl pve-headers-$(uname -r) -y上传驱动包的Host_Drivers文件夹并切换到该文件夹内。在这里使用名为NVIDIA-Linux-x86_64-525.85.07-vgpu-kvm.run的文件演示。
chmod +x ./NVIDIA-Linux-x86_64-525.85.07-vgpu-kvm.run
sh -c ./NVIDIA-Linux-x86_64-525.85.07-vgpu-kvm.run安装流程基本保持默认即可,安装程序会根据当前内核头文件编译安装驱动。同时默认会选择注册dkms模块,在升级内核时会触发自动编译。
如果你的系统开启了安全启动,安装流程会提示对驱动签名并添加信任。相关流程可以参考Linux虚拟机配置部分。
使用dkms status查看驱动模块状态,nvidia-smi查看GPU状态。应当得到类似于如下输出。
❯ dkms status
nvidia, 525.85.07, 5.15.102-1-pve, x86_64: installed
❯ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.07 Driver Version: 525.85.07 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P40 On | 00000000:81:00.0 Off | Off |
| N/A 35C P8 19W / 250W | 16302MiB / 24576MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+此时运行mdevctl types应当可以看到宿主机驱动生成的许多型号不同的mdev设备。至此宿主机驱动部分安装成功。可以通过PVE网页管理面板为虚拟机添加vGPU设备。
分配子设备
可以通过mdevctl types | grep '^[^ ]*$'查看所有生成了mdev的PCI设备ID。打开要添加vGPU虚拟机的硬件面板,添加一个PCI设备。
设备选择刚才查到的设备ID,MDev类型按需选择,可以参考vGPU子设备型号解释小节。一般来说只需考虑显存大小,型号默认选最好的Q(vWS)即可。反正我们不需要为vWS授权付费,Q覆盖了ABC三型号的全部功能,不选白不选。打开高级选项,勾选PCI-Express。
因此除非对i440fx模型有特殊需求,否则q35永远会是更好一些的选择。

点击添加,下次启动时此设备便会附加到虚拟机。至此宿主机已经准备好,该移步虚拟机了。
虚拟机驱动
从驱动包内找到Guest_Drivers并上传至虚拟机。
Windows
双击Guest_Drivers文件夹内528.24_grid_win10_win11_server2019_server2022_dch_64bit_international.exe,跟随安装工具引导安装。
Windows系统的安装流程并没有什么难点。在安装程序结束后,打开PowerShell,执行nvidia-smi.exe。如果得到类似于如下的输出,代表驱动已经成功识别分配给虚拟机的子设备。
PS C:\> nvidia-smi.exe
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 528.24 Driver Version: 528.24 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GRID P40-8Q WDDM | 00000000:01:00.0 On | N/A |
| N/A 0C P0 N/A / N/A | 636MiB / 8192MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+nvidia-smi.exe -q | Select-String License,可以看到如下输出。输出表明此时驱动未授权,但因为刚启动时间不长,尚未限制性能。如果持续使用一段时间就会弹出GPU性能受限的提示。
PS C:\Users\Chieru> nvidia-smi.exe -q | Select-String License
vGPU Software Licensed Product
License Status : Unlicensed (Unrestricted)至此驱动安装已经完成,下一节再来解决授权的问题。
Linux
首先与宿主安装驱动的准备工作类似,禁用nouveau并安装必须软件包。
echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.conf
update-initramfs -k all -u
apt install build-essential dkms mdevctl -y
reboot切换到Guest_Drivers文件夹
chmod +x ./NVIDIA-Linux-x86_64-525.85.05-grid.run
sh -c ./NVIDIA-Linux-x86_64-525.85.05-grid.run等待驱动安装程序验证数据完整性并构建驱动。
如果使用了q35+OMVF(UEFI)的话,应当默认开启了安全启动。如果没有在安装过程看到类似于下图的界面的话,那么可以忽略安装驱动时签名部分与重启时Mok信任证书部分。
如果怕麻烦也可以直接选择不签名并从BIOS手动关闭安全启动,关闭位置为虚拟机启动显示Proxmox VE的LOGO时按F2进入BIOS,Device Manager -> Secure Boot Configuration -> Attempt Secure Boot,取消勾选并保存。
对于开启了安全启动的系统,需要对驱动进行签名。使用左右箭头选择Sign the kernel module,回车确认。

因为没有密钥对,因此选择生成一对。选择Generate a new key pair。
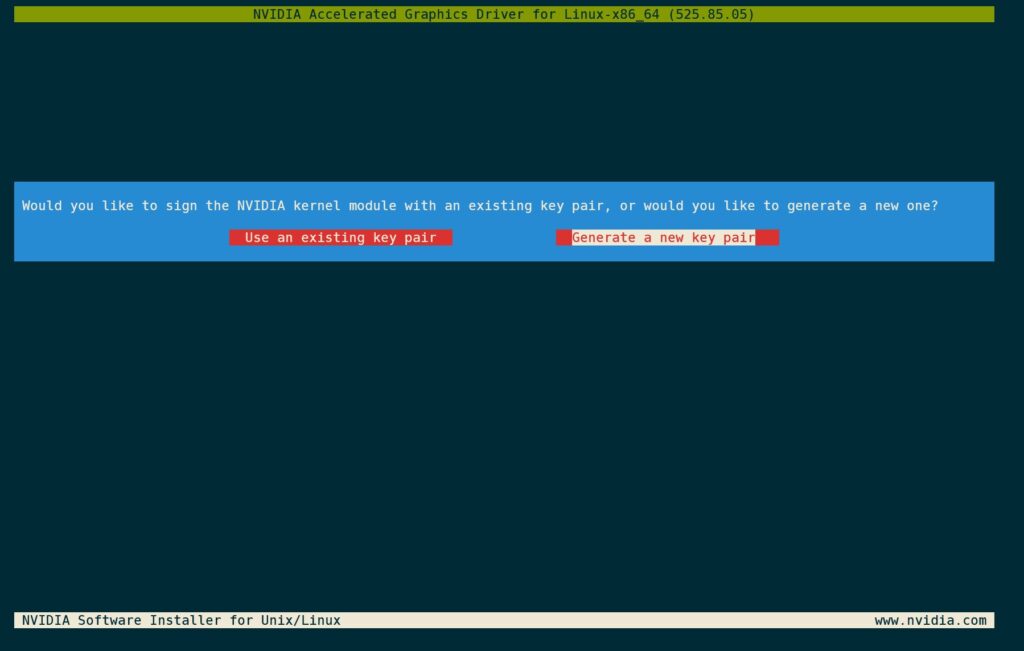
签名已经完成了。为安全起见,删除签名使用的私钥。选择Yes。

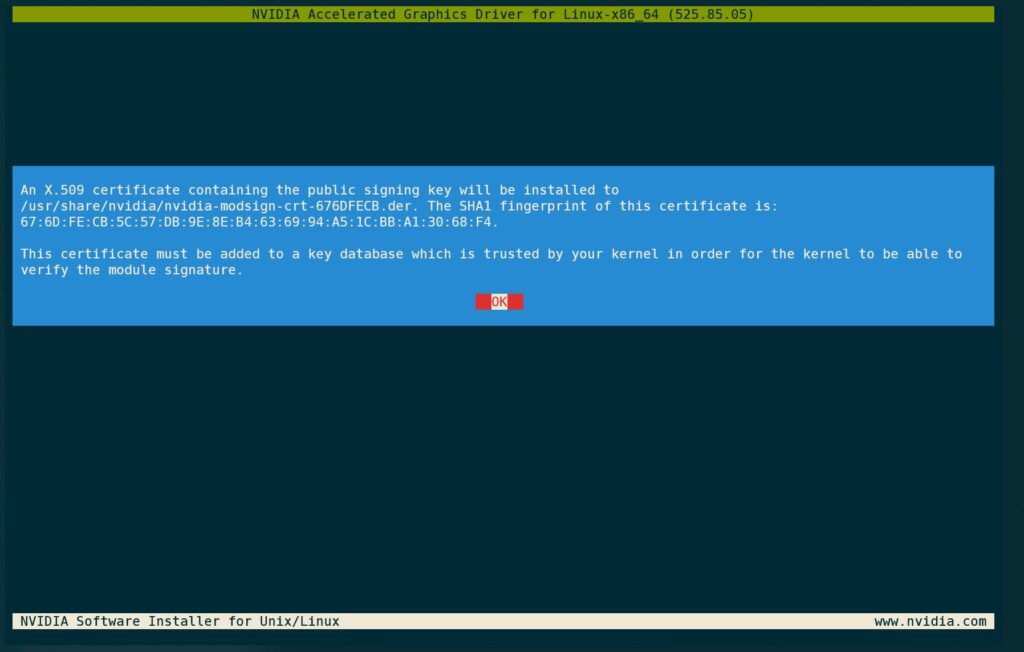
安装程序提示需要将信任签名证书加入内核的信任列表,记住此处提示的证书路径。
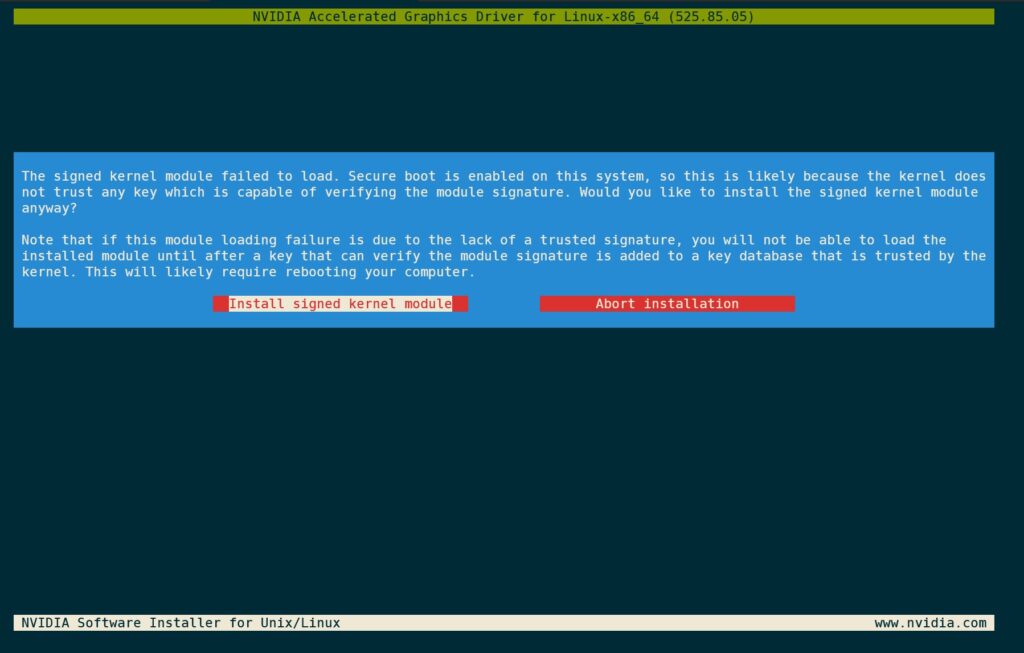
安装程序提示说目前内核并不信任刚刚签名完成的驱动。这是因为还没有添加证书信任。选择Install signed kernel module即可。
其余选项没什么需要注意的,均保持默认即可。32位兼容库看个人需要,此处博主选择安装。默认会注册DKMS,不需要改动。
看到此界面代表安装完毕。

根据提示,需要信任刚刚生成的证书。使用mokutil导入证书,其中证书名称的指纹部分根据刚才显示的填写。如果不记得可使用Tab让系统补全,如果曾经签名过导致有多张的话可以按文件创建时间判断。
mokutil --import /usr/share/nvidia/nvidia-modsign-crt-676DFECB.der此处会提示创建一个导入密码,记住此处设置的密码,稍后会用到。reboot命令重启系统。
启动流程应当会显示以下界面,需要在超时前按任意键进入MokManage。
Failed to open \EFI\BOOT\mmx64.efi - Not Found的报错,代表默认使用了\EFI\BOOT启动,但缺失了MokManager。对于一部分情况,EFI分区内包含了两组引导文件,但系统默认使用了缺失Mok的。可以通过在BIOS手动添加启动选项解决。
Boot Maintaince Manager -> Boot Options -> Add Boot Option,添加EFI分区下另一文件夹的shimx64.efi并修改启动顺序。如果EFI内确实无Mok,或者不愿意折腾,可以通过删除EFI磁盘并重新添加的方式救援。关闭安全启动并安装不签名的驱动即可。
按任意键后会进入Mok管理界面。因为此前使用了mokutil创建了导入请求,此处会显示Enroll MOK的选项,选择此项。
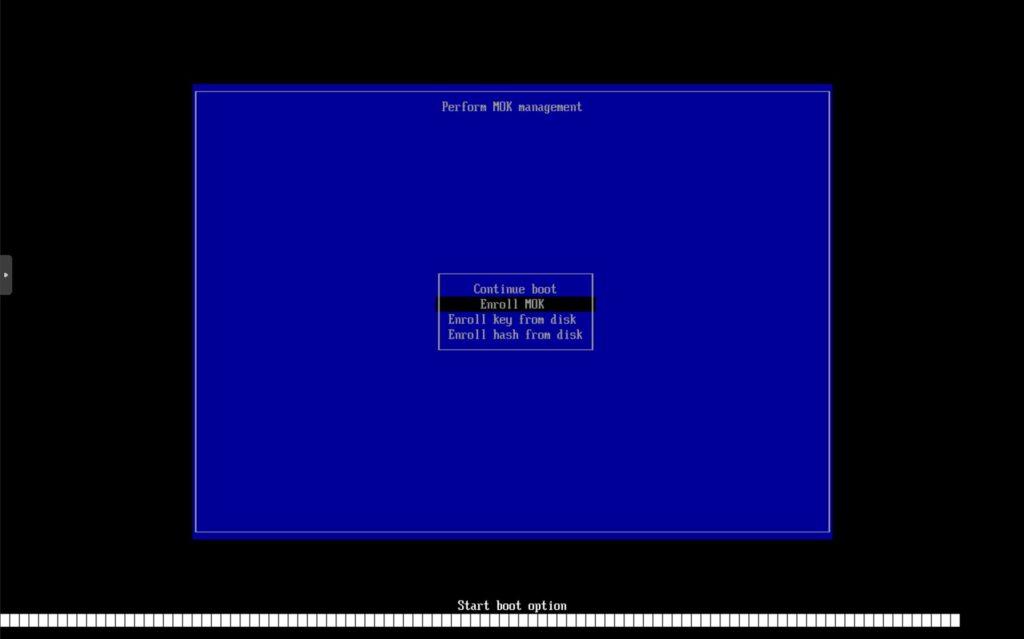
此处列出了可以导入的请求。严谨角度来说应当核对指纹来确认导入目标,但因为此处只有一个,所以可以直接选择继续。
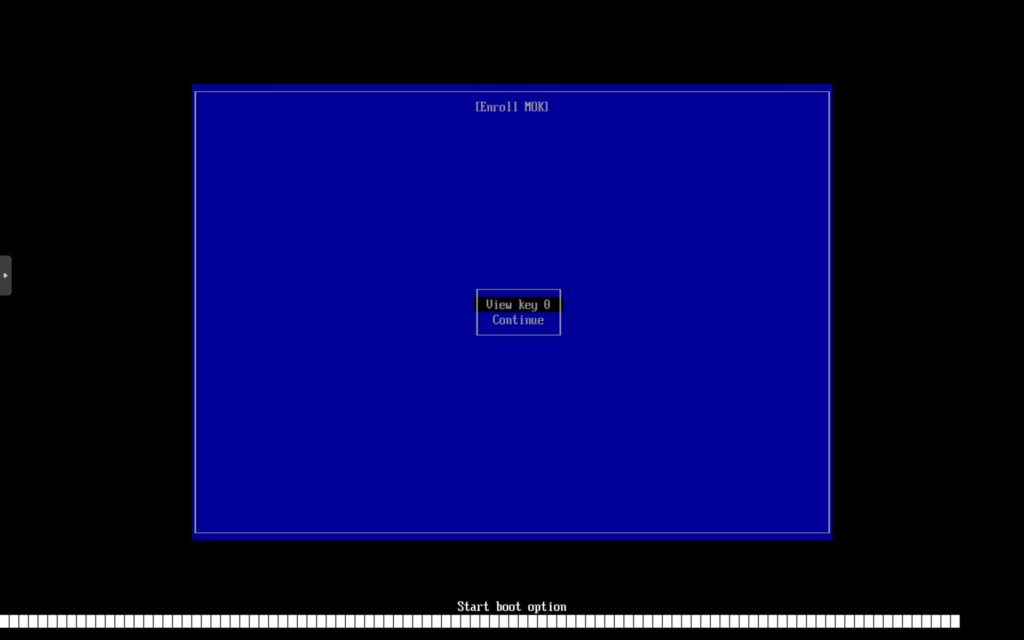
选择确认导入,并输入刚才设置的导入密码。注意此处输入无回显,输入完成后回车确认。
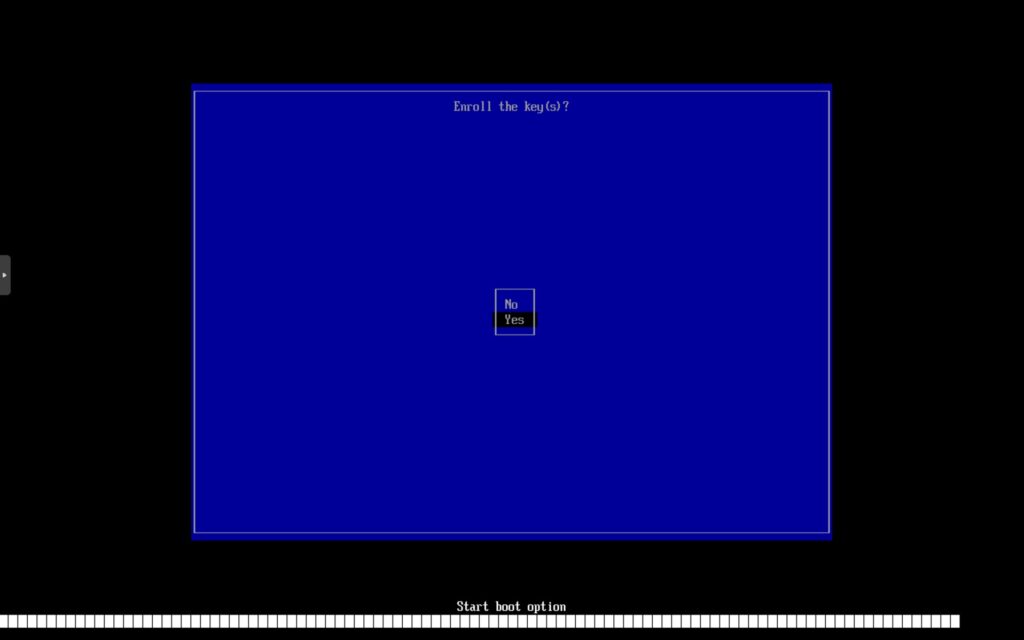

如果密码无误会回到Mok管理界面首页,但是出现了重启的选项。选择重启。
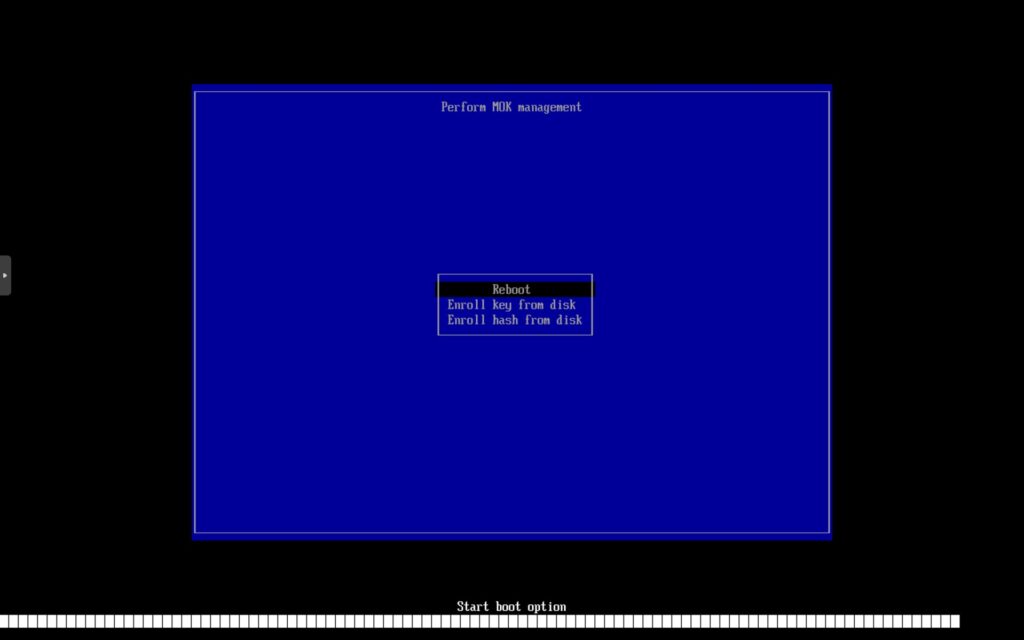
等待系统启动完成,使用dkms status和nvidia-smi查看安装状态,参考输出如下。
root@VM133:~# dkms status
nvidia, 525.85.05, 5.10.0-21-amd64, x86_64: installed
root@VM133:~# nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GRID P40-8Q On | 00000000:01:00.0 Off | N/A |
| N/A N/A P8 N/A / N/A | 0MiB / 8192MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+nvidia-smi -q | grep License查看订阅状态,输出如下。
root@VM133:~# nvidia-smi -q | grep License
vGPU Software Licensed Product
License Status : Unlicensed (Unrestricted)可以看到尚未授权,在下一节我们将搭建授权服务器并为虚拟机驱动授权。
DLS服务器搭建与应用
上文已经提到过,博主将使用FastAPI-DLS[8]实现授权。令人欣喜的是,项目作者提供了Docker部署方式,同时给出了参考的Compose配置。
这里博主使用了一个LXC容器来作为承载Docker的环境。相对于虚拟机,LXC容器更加轻量化。DLS作为面向整个虚拟化平台的基础服务,快一些的启动速度总是没错的。创建容器与安装Docker的部分与主题无关,在此略去。
zfs对于该问题的修复性更新在zfs2.2版本合入。根据Proxmox工作人员回复[13],PVE会在zfs2.2的rc结束正式发布后更新到zfs2.2。因此PVE上的问题将在届时得到修复。
Minor patch #1.1 At 2024.02.26:
根据Roadmap,PVE8.1版本已经升级到了ZFS 2.2.0。理论上此时已经可以在非特权LXC上正常安装docker而不需要额外操作了
搭建服务器
创建证书目录并生成证书密钥。
WORKING_DIR=/opt/docker/fastapi-dls/cert
mkdir -p $WORKING_DIR
cd $WORKING_DIR
openssl genrsa -out $WORKING_DIR/instance.private.pem 2048
openssl rsa -in $WORKING_DIR/instance.private.pem -outform PEM -pubout -out $WORKING_DIR/instance.public.pem
openssl req -x509 -nodes -days 3650 -newkey rsa:2048 -keyout $WORKING_DIR/webserver.key -out $WORKING_DIR/webserver.crt切换到~,新建一个docker-compose.yml,写入如下内容,记得更改DLS_URL。对于证书有效期,作者在某个版本的文件中提到最长为90日,但博主尝试了更长的时间,驱动也能正常识别并显示过期时间。如果不愿意冒险,可以设为90。
version: '3.9'
x-dls-variables: &dls-variables
TZ: Asia/Shanghai
DLS_URL: localhost # 修改此处为此DLS服务器的IP或域名
DLS_PORT: 443
LEASE_EXPIRE_DAYS: 1800 # 证书有效期默认为90天
DATABASE: sqlite:////app/database/db.sqlite
DEBUG: false
services:
dls:
image: collinwebdesigns/fastapi-dls:latest
restart: always
environment:
<<: *dls-variables
ports:
- "443:443" # 内部端口固定为443。要修改DLS的端口,同步修改冒号前的值与DLS_PORT的值
volumes:
- /opt/docker/fastapi-dls/cert:/app/cert
- dls-db:/app/database
logging:
driver: "json-file"
options:
max-file: 5
max-size: 10m
volumes:
dls-db:使用docker compose up -d启动,用浏览器访问https://DLS_URL:DLS_PORT/-/readme。如果可以打开代表服务器已经上线。
Windows授权
使用管理员身份启动PowerShell,替换DLS_URL:DLS_PORT为自己的设置。
curl.exe --insecure -L -X GET https://DLS_URL:DLS_PORT/-/client-token -o "C:\Program Files\NVIDIA Corporation\vGPU Licensing\ClientConfigToken\client_configuration_token_$($(Get-Date).tostring('dd-MM-yy-hh-mm-ss')).tok"
Restart-Service NVDisplay.ContainerLocalSystem驱动检测到证书后会弹出提示,标明了过期时间。
nvidia-smi.exe -q | Select-String License,可以看到状态已经变为已授权了。可以看到,时长接近五年的授权也可以正常显示。
PS C:\> nvidia-smi.exe -q | Select-String License
vGPU Software Licensed Product
License Status : Licensed (Expiry: 2028-1-09 9:34:5 GMT)如果需要为授权花钱的话,这是一个非常严重的问题。但是巧的是我们不需要。
如果想要修复这个问题,可以参考作者给出的加入nginx反代的docker-compose.yml
Linux授权
root执行如下命令,替换DLS_URL:DLS_PORT为自己的设置。
echo "FeatureType=2" >> /etc/nvidia/gridd.conf
curl --insecure -L -X GET https://DLS_URL:DLS_PORT/-/client-token -o /etc/nvidia/ClientConfigToken/client_configuration_token_$(date '+%d-%m-%Y-%H-%M-%S').tok
service nvidia-gridd restartnvidia-smi -q | grep License查看订阅状态,确认授权生效。
root@VM133:~# nvidia-smi -q | grep License
vGPU Software Licensed Product
License Status : Licensed (Expiry: 2028-1-13 17:33:13 GMT)如果需要手动配置授权或遇到问题,可以参考Licensing an NVIDIA vGPU。
结束了……吗?
“勇者历经重重磨难击败了恶龙,故事的下一节该是和公主过上幸福的生活了吧?”
“错啦,答案是勇者差点被路边的小石子绊到死亡陷阱里嘛。”
详见Roadmap – Proxmox VE的Changelog Overview部分,原文如下:
“Workaround breaking driver changes in newer Nvidia grid drivers, which prevented mediated devices (mdev) to be reclaimed upon guest exit.”
因此使用PVE 8.0+的读者可以忽略本部分。
先给出解决方法:把这个patch打到/usr/share/perl5/PVE/QemuServer.pm上,修补后的cleanup_pci_devices函数大概长下面这样。
sub cleanup_pci_devices {
my ($vmid, $conf) = @_;
foreach my $key (keys %$conf) {
next if $key !~ m/^hostpci(\d+)$/;
my $hostpciindex = $1;
my $uuid = PVE::SysFSTools::generate_mdev_uuid($vmid, $hostpciindex);
my $d = parse_hostpci($conf->{$key});
if ($d->{mdev}) {
# NOTE: avoid PVE::SysFSTools::pci_cleanup_mdev_device as it requires PCI ID and we
# don't want to break ABI just for this two liner
my $dev_sysfs_dir = "/sys/bus/mdev/devices/$uuid";
# some nvidia vgpu driver versions want to clean the mdevs up themselves, and error
# out when we do it first. so wait for 10 seconds and then try it
my $pciid = $d->{pciid}->[0]->{id};
my $info = PVE::SysFSTools::pci_device_info("$pciid");
if ($info->{vendor} eq '10de') {
sleep 10;
}
PVE::SysFSTools::file_write("$dev_sysfs_dir/remove", "1") if -e $dev_sysfs_dir;
}
}
PVE::QemuServer::PCI::remove_pci_reservation($vmid);
}好了,你已经迈过这颗小石子了,赶快去找你的公主吧。
如果你愿意看下去,那博主就来讲讲这颗小石子。
Bug表现为任何分配了vGPU的设备,关机任务有高概率卡死。哪怕强行停止,也会发现本应释放的mdev没有被释放,通过nvidia-smi仍能看到它在占用显存。但诡异的是,mdevctl给出了不同的另一套结果。如果查看dmesg,可以看到vGPU destroy failed的日志,伴随着大量的exception trace信息。此时,这个小石子已经影响到了宿主机的稳定。最严重的一次,这个问题导致PVE宿主机在关机阶段死机,逼迫博主硬重置了整台宿主机。
按下追寻Bug的艰辛不表,总之勇者对着那颗小石头摔了四天的跤。倘若换成打魔王现在都该和公主办婚礼了,可惜换不得。直到最后,终于想起来那行vGPU destroy failed可能不是元凶而是受害人。
最终博主在这篇帖子找到了完整的分析和解决方案。简单来说,最新的15.*宿主驱动会在虚拟机关闭时主动回收mdev。但PVE也会做同样的事,并且抢在了宿主驱动前,驱动试图回收已经不存在的mdev时遇到了异常。
修复方式就是对Nvidia的mdev延迟回收,留给宿主驱动足够的时间来完成回收。如果宿主驱动完成了回收,PVE会直接返回;而如果这是旧版的宿主驱动,那么PVE会在延时后完成清理。这种修复方式会导致关机/停止等任务执行时间延长,但目前为止博主没有找到更好的办法。
后记
光看本次的引用部分长度,就能知道事情似乎不同寻常。
这还是最接近原生授权模式的FastAPI-DLS,vgpu_unlock作为魔改方案只会更加复杂。
幸运的是,尽管身上带着补丁,这套系统总算是比较完美地跑起来了。经过了约一个月的稳定性测试,博主用到了vGPU的windows和jellyfin都工作得很好。Homelab系列至此也完成了几乎全部硬件相关的部分,后期可能只会包括一些软件设施方面的记录了。
希望本文能帮助对vGPU有需求的人。
补充资料目录
本文仍有许多缺漏,如有不解之处可以参考本部分的资料。
本vGPU配置过程或多或少地参考了这些资料,衷心感谢付出时间提供教程与资源的各位。如果没有这些帮助,博主可能需要多耗费许多时间达成目标。
教程
NVIDIA vGPU Guide[14]
Proxmox VE Nvidia-vGPU 中文教程[15]
vGPU教程 – 国光的 PVE 环境搭建教程[16]
PVE Docker使用Tesla P4 VGPU[17]
PVE+Tesla P4 vGPU All IN ONE NAS 折腾小记[18]
于proxmox的lxc中安装vgpu授权服务笔记[19]
来自民间的VGPU授权fastapi-dls[20]
在Proxmox VE 7.2 中开启vGPU_unlock,实现显卡虚拟化[21]
手册
Virtual GPU Software User Guide[22]
NVIDIA vGPU on Proxmox VE 7.x[23]
vGPU资源信息[24]
项目/资源
FastAPI-DLS[8]
vgpu_unlock-rs[7]
Index of /NVIDIA/ (biggerthanshit.com)(失效)[25]
vGPU | HomeLabProject’s List(可用) [26]
vGPU Archive Index(推荐使用) [27]
适用于 NVIDIA RTX 虚拟工作站的驱动程序(仅包含guest驱动)[28]
NVIDIA-VGPU-Driver-Archive(推荐使用 删库了)[29]
升级不完全指北 Update#1
本节作为Update#1内容,放在了比参考资料还要靠后的地方。
本节将记录由GRID 15.1升级到16.1的全过程。
升级的理由一半是因为PVE8.0使用6.2内核需求更高版本驱动,另一半则是因为vGPU 16是LTS版本,费事这一次可以省事好几年。
尽管理论上不会有问题,但你应当了解升级的风险,并明白自己在做什么。
你已经被警告过了!
驱动包准备
从此处[29]下载NVIDIA-GRID-Linux-KVM-535.104.06-535.104.05-537.13.zip。
宿主驱动更新
关闭所有分配了vGPU的虚拟机,确保其中的mdev被释放,否则安装脚本会在Pre-unload hook失败。
上传Host_Drivers文件夹下的文件至PVE宿主,然后启动安装。
chmod +x ./NVIDIA-Linux-x86_64-535.104.06-vgpu-kvm.run
sh -c ./NVIDIA-Linux-x86_64-535.104.06-vgpu-kvm.run安装脚本检测到已经安装了旧版本驱动,安装新的会卸载旧的,选择继续安装即可。
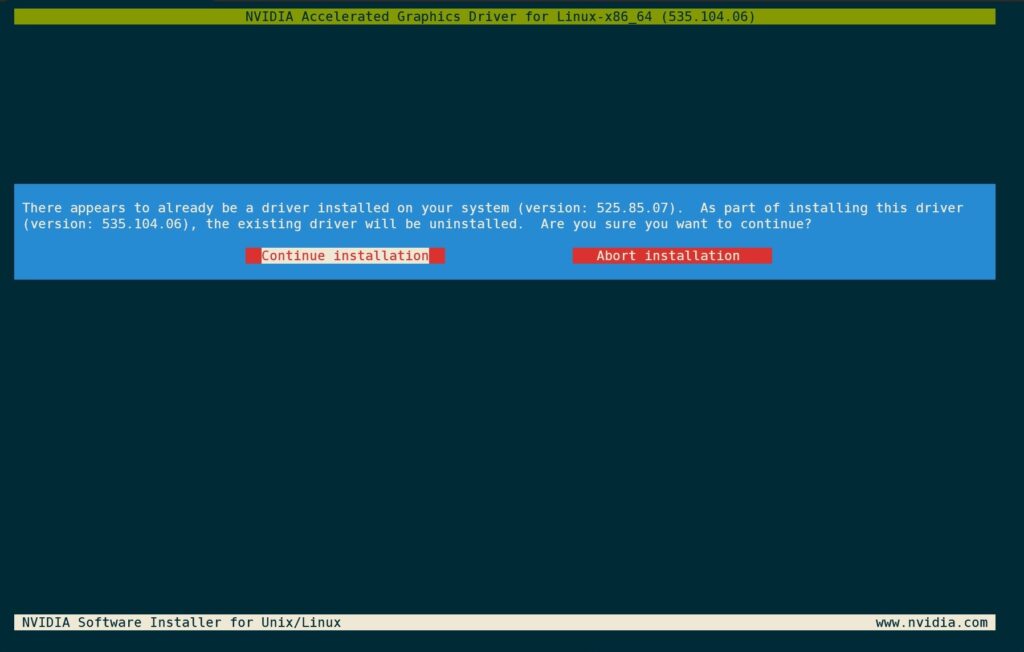
是否注册DKMS模块,选择是。

看到本界面说明安装完成。

使用命令确认版本。输出类似如下内容:
❯ dkms status
nvidia, 535.104.06, 5.15.102-1-pve, x86_64: installed
❯ nvidia-smi
Tue Oct 3 23:29:35 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.06 Driver Version: 535.104.06 CUDA Version: N/A |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla P40 Off | 00000000:81:00.0 Off | Off |
| N/A 44C P0 53W / 250W | 54MiB / 24576MiB | 1% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
虽然此时驱动版本已经变了,但是此时mdevctl types还无法列出mdev。
稳妥起见,关掉所有分配vGPU虚拟机的开机自启,然后重启PVE宿主机。
重启后,mdevctl types应当可以输出所有的mdev了。确认无误后可以恢复相关虚拟机的开机自启设置,并且启动这些虚拟机。
虚拟机驱动更新
Windows
运行Guest_Drivers内537.13_grid_win10_win11_server2019_server2022_dch_64bit_international.exe。
一路确定,等待安装完成即可。推荐在安装时断开各类远程桌面,使用PVE自带的控制台,以免安装故障时丢失对虚拟机的控制。
安装完成后通过nvidia-smi确定驱动版本如下:
PS C:\> nvidia-smi.exe
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 537.13 Driver Version: 537.13 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 GRID P40-8Q WDDM | 00000000:01:00.0 On | N/A |
| N/A 0C P0 N/A / N/A | 605MiB / 8192MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+如果此前配置了fastapi-dls的话,驱动更新完成后应当弹出如下许可证状态:

通过命令查询许可证状态如下:
PS C:\Users\Chieru> nvidia-smi.exe -q | Select-String License
vGPU Software Licensed Product
License Status : Licensed (Expiry: 2028-9-28 18:3:33 GMT)
保险起见,重启虚拟机。虚拟机驱动更新完成。
Linux
运行Guest_Drivers内NVIDIA-Linux-x86_64-535.104.05-grid.run。
chmod +x ./NVIDIA-Linux-x86_64-535.104.05-grid.run
sh -c ./NVIDIA-Linux-x86_64-535.104.05-grid.run首先是类似于更新宿主驱动时的覆盖安装提示,确认即可。
如果启用了安全启动,需要签名并信任。本部分可以参考初次安装Linux虚拟机驱动部分的流程。此处略过导入证书流程,且默认驱动安装完成且虚拟机已经重启过。
通过命令确认驱动版本如下:
❯ dkms status
nvidia, 535.104.05, 5.10.0-21-amd64, x86_64: installed
❯ nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 GRID P40-8Q On | 00000000:01:00.0 Off | N/A |
| N/A N/A P8 N/A / N/A | 0MiB / 8192MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+确认授权状态:
❯ nvidia-smi -q | grep License
vGPU Software Licensed Product
License Status : Licensed (Expiry: 2028-10-1 16:20:33 GMT)虚拟机驱动更新完成。
请教一下,VGPU那个授权服务器的DOCKER我设置的是90天, 如果到期了他会自动续吗? 还是需要自己重新再建docker?
只要能访问到DLS就会自动续签。
完整的答案:授权有效期不足时Guest会多次尝试连接证书服务器(也就是那个docker)续签,我印象中尝试续签的缓冲期也是可以配置的。只要保证缓冲期内能见到一次活着的DLS就可以。
那就是说,docker我只要一直保持着有网络 不动它, 那些客户机WINDOWS 可以正常连接 ,我就不用管了, 快到期那些windows会自动从docker那个主机上获取新的授权 是这样么 谢谢解惑
请问pve升级之后,驱动要重新安装吗?
一般不需要。PVE升级唯一跟驱动有关的是内核版本,一般来说内核升级时dkms会处理一切。
但是,如果要更新到的PVE内核版本不再支持旧版本驱动的话,需要更新驱动,如文中Update#1 7.x升级8.0部分。
你有遇到过内存泄漏的问题吗,加了vgpu后,宿主机的内存增加了很多
好像没有注意到类似的问题
我宿主机这边top看了一下,没有看到可疑的进程
如果可以的话,先关掉dls和虚拟机的ballooning排查一下?
先排除一下授权服务器和虚拟机本身占用的问题
你好 这个教程特别有用 感谢
但我还是卡在最后的最后
我所有的流程都走完了,pve8,2上安装host driver, win11 vm上安装guest driver也成功,无论pve还是windows vm都显示正常 (nvidia-smi, windows task manager) parsec也能正常hardware encoding。我用的是535的host driver,528的guest driver。
但只要我重启装好driver的windows vm,vm就会挂。表现是直接蓝屏然后自动重启, 或是启动了但novnc卡住+parsec无法检测。remove gpu后又能启动了。
请问你有遇到过这个问题吗?
pve8.1+537.13没有见到过类似的情况。重启可能会很慢,但是应该不会蓝屏。这个问题是仅在重启时出现,还是先关机再开机也会有同样的问题?
不过建议首先统一host和guest的版本。我没有查到跨版本使用的案例,猜测可能会导致一些意料之外的问题。另外重装win11可能会有一些帮助。
如果一切都试了还没有头绪,那建议从宿主端查mdev状态、系统日志是否有异常;从虚拟机查驱动日志和事件信息,看看蓝屏的直接原因是什么。
内容很好
哇哦,写的真好。受益匪浅,非非非非常感谢博主的分享!